

NVIDIA ’s next-gen Blackwell GPUs are not a gentle upgrade; they are a seismic jolt that rewrites the playbook for large-language-model (LLM) builders, cloud platforms, and, yes, investors. Today we unpack the specs, the dollars, and the ripple effects— all in plain English, just like a quick finance chat on Akshat Srivastava’s channel.
NVIDIA Blackwell Basics – Why This Chip Matters
NVIDIA’s Hopper H100 already feels fast. Even so, Blackwell’s flagship B200 doubles memory, more than doubles bandwidth, and leaps from gigaflops to petaFLOPs in AI math. In turn, LLM teams can train fatter models in fewer days while slashing energy per token. Consequently, the barrier to test frontier ideas collapses.
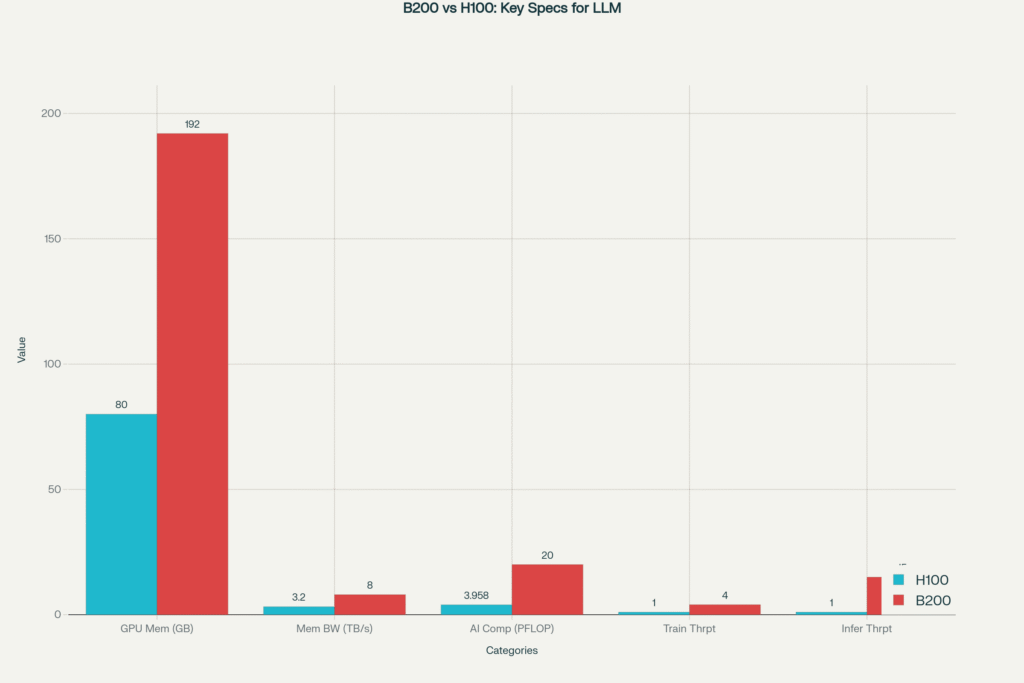
Blackwell B200 towers over Hopper H100 across memory, bandwidth and AI throughput metrics crucial for next-gen LLMs
Moreover, Blackwell’s transformer engine now speaks FP4 and FP6. Therefore, model weights shrink, batches bloat, and GPU memory no longer feels cramped. Additionally, fifth-gen NVLink glues GPUs together at 1.8 TB/s, so 8-way DGX B200 boxes act like one giant brain.
How NVIDIA Blackwell Changes LLM Training Economics
First, training time falls. Four B200 nodes can deliver roughly the same throughput as sixteen H100 nodes, because each GPU shovels data faster and computes at 20 PFLOPs of sparse FP4. Second, hardware hours drop. If an H100 cluster consumed 5,000 GPU-days to reach a quality target, the same target may arrive in 1,200 GPU-days on B200. Consequently, electricity and cloud-rental bills fall even if hourly prices rise.
Third, memory headroom means teams no longer shard every layer. Thus, code becomes simpler, failure rates decline, and developer velocity rises. Ultimately, product cycles compress; what once needed quarters now squeezes into weeks.
Cost Math: What Cloud Pricing Tells Us
Yes, B200 rental still costs more per hour, yet the gap is narrower than many expect. Runpod lists H100 at $2.99/hr and B200 at $5.99/hr. Lambda Labs presses that gap to barely a dollar. Because training minutes plunge, total spend often breaks even or improves.
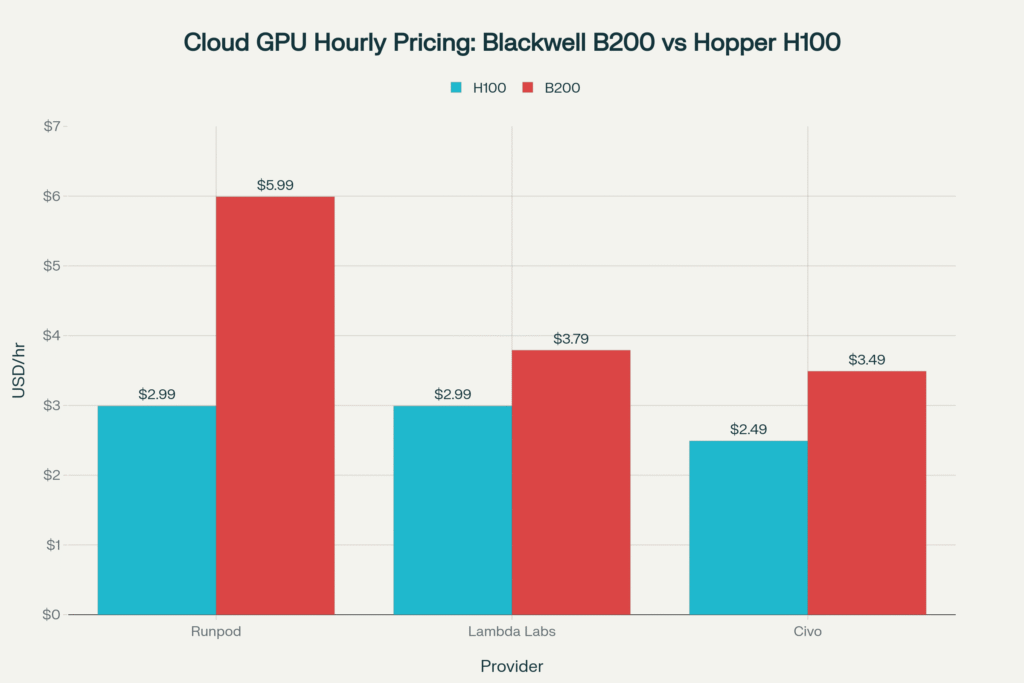
Hourly cloud pricing still favors H100, yet efficiency gains can tilt total cost of training in B200’s favour
Imagine a 70-billion-parameter model that needs 10,000 H100 hours but only 3,000 B200 hours. Even at a 2× hourly premium, the B200 bill is smaller. Moreover, inference sees a 15× tokens-per-second jump, so serving costs tumble as well.
Performance Impact on Model Quality and Size
Bigger context windows and long-thinking loops become affordable. Consequently, research groups can move from 30 B to 300 B parameters without heroic parallel tricks. Meanwhile, FP4 precision keeps accuracy high by using micro-tensor scaling; hence, loss curves stay smooth. Early tests by independent labs show 4× cluster-level training throughput and 30× real-time inference gains on trillion-token datasets12.
Furthermore, the 192 GB HBM3e plus 8 TB/s bandwidth lets a single Blackwell GPU host entire 20-B parameter MoE models. Therefore, edge inference on compact servers becomes realistic, unlocking private deployments in regulated industries.
Strategic Shift: What This Means for Competitors and AI Start-ups
Because Blackwell raises the floor, small labs no longer need mega-scale budgets to chase state-of-the-art accuracy. Start-ups can rent eight B200s for under $30/hr on Civo and crank a 7-B model refresh in a weekend. Meanwhile, AMD’s MI300X and Google’s TPU v6 now face a moving target set a year ahead.
Cloud chains—AWS, Oracle, CoreWeave—have already ordered multi-exaflop Blackwell pods. SoftBank’s 4,000-GPU DGX SuperPod in Japan is live3. Hence, supply tightness persists, yet the queue grows longer for Hopper rather than Blackwell, nudging hyperscalers to pivot inventories faster.
Market Impact for NVIDIA Shareholders
Data-center revenue hit $26.3 bn last quarter, up 154% YoY, even before Blackwell shipped in volume45. Management guides double-digit billions of Blackwell sales in fiscal Q4 2025. Additionally, richer software subscriptions (AI Enterprise, NeMo, Spectrum-X) ride on every DGX. Thus, margin mix remains thick despite cap-ex surges. Investors itching for “peak GPU” might rethink; the compute scaling law is still steep, and Blackwell resets it upward.
Risks and Bottlenecks
However, supply chain is thin. HBM3e yields, TSMC 4NP wafer capacity, and CoWoS packaging all constrain rollout. Furthermore, power draw climbs to 14 kW per DGX B200 rack, stressing data-center cooling budgets. Regulatory export limits can also divert volumes. Finally, although FP4 rocks on current benchmarks, real-world robustness across languages and edge cases needs fresh validation.
Actionable Takeaways for Developers and Investors
- Plan migrations early. Software stacks (CUDA 13, TensorRT-LLM 1.0) already support FP4; port models now to harvest gains once B200 nodes appear in your region.
- Model-size rethink. Re-balance width vs. depth, use larger experts, and exploit the extra memory to fit bigger batches; training curves flatten faster.
- Budget smarter. Compare cost per completed epoch, not per GPU-hour. Even pricier B200 rentals can undercut Hopper clusters.
- Watch inference latency. Blackwell cuts token delay under 5 ms for 7-B models; product managers can unlock new real-time use-cases.
- Invest with caution. Valuation is rich, yet secular tailwinds and new software revenue keep fundamentals strong; stagger entries.
Conclusion
In summary, NVIDIA Blackwell is not just a chip upgrade; it is a force multiplier that compresses costs, expands model ambition, and tilts the competitive field. As B200 racks light up worldwide, expect faster AI breakthroughs, cheaper inference, and a renewed arms race in silicon. For builders, the advice is simple: migrate early, exploit FP4, and ride the wave. For investors, keep an eye on supply, margins, and software attach rates. The LLM game has a fresh scoreboard, and NVIDIA just wrote the new rules.
You Might also find this post insightful – https://bosslevelfinance.com/grok-4-crushes-ai-giants-why-its-dominating-2025
Source Links
- primeLine B200 Datasheet
- ExitTechnologies—H100 vs B100 analysis
- NVIDIA DGX B200 User Guide
- Corvex cost guide
- Geeky-Gadgets Blackwell specs
- NVIDIA DGX B200 page
- Tweaktown Blackwell tease
- PNY DGX B200 specs
- LinkedIn LLM cost post
- WandB Blackwell architecture deep dive
- TechPowerUp B200 specs
- TechInsights teardown
- Scan DGX B200 appliance
- LinkedIn training cost article
- NVIDIA Blackwell architecture site
- NVIDIA DGX B200 datasheet
- Runpod Blackwell guide
- DatacenterDynamics SoftBank B200 cluster
- Modal B200 hourly pricing blog
- Runpod B200 page
- Lambda Labs pricing
- Civo B200 pricing
- MLQ.ai NVIDIA Q2 25 earnings
- NVIDIA newsroom Q2 25 release
- NVIDIA FY25 Q4 results
- MediaNama earnings summary
- https://wandb.ai/onlineinference/genai-research/reports/NVIDIA-Blackwell-GPU-architecture-Unleashing-next-gen-AI-performance–VmlldzoxMjgwODI4Mw
- https://www.nvidia.com/en-in/data-center/technologies/blackwell-architecture/
- https://www.datacenterdynamics.com/en/news/softbank-deploys-4000-strong-nvidia-b200-dgx-superpod-cluster-for-japanese-llm-development/
- https://nvidianews.nvidia.com/news/nvidia-announces-financial-results-for-second-quarter-fiscal-2025
- https://www.medianama.com/2024/08/223-nvidias-q2fy25-earnings-data-center-revenue-ai-cloud-services/
- https://www.primeline-solutions.com/media/categories/server/nach-gpu/nvidia-hgx-h200/nvidia-blackwell-b200-datasheet.pdf
- https://exittechnologies.com/blog/gpu/nvidia-h100-vs-b100/
- https://docs.nvidia.com/dgx/dgxb200-user-guide/introduction-to-dgxb200.html
- https://www.corvex.ai/blog/what-are-the-true-costs-of-training-llms
- https://www.geeky-gadgets.com/nvidia-blackwell-gpu/
- https://www.nvidia.com/en-in/data-center/dgx-b200/
- https://www.tweaktown.com/news/94338/nvidia-officially-teases-next-gen-b100-blackwell-gpu-over-4x-as-fast-h100-ai/index.html
- https://www.pny.com/en-eu/nvidia/dgx/b200
- https://www.linkedin.com/posts/levselector_how-much-does-it-cost-to-train-an-llm-on-activity-7115319676301099008-i9fS
- https://www.techpowerup.com/gpu-specs/b200-sxm-192-gb.c4210
- https://www.electronicspecifier.com/products/artificial-intelligence/techinsights-releases-analysis-of-nvidia-blackwell
- https://www.scan.co.uk/business/nvidia-dgx-b200
- https://www.linkedin.com/pulse/what-cost-training-large-language-models-cudocompute-0o7kc
- https://resources.nvidia.com/en-us-dgx-systems/dgx-b200-datasheet
- https://www.runpod.io/articles/guides/nvidias-next-gen-blackwell-gpus-should-you-wait-or-scale-now
- https://www.cudocompute.com/blog/what-is-the-cost-of-training-large-language-models
- https://www.nvidia.com/en-us/data-center/technologies/blackwell-architecture/?pStoreID=techsoup%270
- https://www.nvidia.com/en-in/data-center/h100/
- https://nvidia.github.io/TensorRT-LLM/blogs/H100vsA100.html
- https://www.megware.com/fileadmin/user_upload/LandingPage%20NVIDIA/nvidia-h100-datasheet.pdf
- https://lambda.ai/blog/nvidia-hopper-h100-and-fp8-support
- https://nvidianews.nvidia.com/news/nvidia-announces-dgx-h100-systems-worlds-most-advanced-enterprise-ai-infrastructure
- https://www.res.restargp.com/wp1/wp-content/uploads/2023/01/nvidia-h100-datasheet-2287922-web.pdf
- https://jarvislabs.ai/ai-faqs/what-is-the-flops-performance-of-the-nvidia-h100-gpu
- https://www.shi.com/product/45671009/NVIDIA-H100-GPU-computing-processor
- https://uvation.com/articles/guide-to-h100-fp8
- https://developer.nvidia.com/blog/achieving-high-mixtral-8x7b-performance-with-nvidia-h100-tensor-core-gpus-and-tensorrt-llm/
- https://rptechindia.com/nvidia-dgx-h100.html
- https://www.civo.com/blog/comparing-nvidia-b200-and-h100
- https://www.colfax-intl.com/nvidia/nvidia-h100
- https://datacrunch.io/blog/nvidia-h100-gpu-specs-and-price
- https://developer.nvidia.com/blog/nvidia-hopper-architecture-in-depth/
- https://www.exxactcorp.com/blog/hpc/comparing-nvidia-tensor-core-gpus
- https://modal.com/blog/nvidia-b200-pricing
- https://www.qubrid.com/pricing/
- https://www.amaryllo.us/pricing
- https://www.runpod.io/gpu-models/b200
- https://lambda.ai/pricing
- https://www.genesiscloud.com/products/nvidia-hgx-b200
- https://www.runpod.io/pricing
- https://gcore.com/pricing
- https://www.hyperstack.cloud/nvidia-blackwell-b200
- https://www.runpod.io/articles/guides/b200-ai-research
- https://www.civo.com/newsroom/nvidia-gpus-from-0-69-per-hour
- https://lambda.ai/service/gpu-cloud
- https://www.spotsaas.com/product/runpod/pricing
- https://nebius.com/prices
- https://www.cudocompute.com/products/gpu-cloud/nvidia-b100
- https://getdeploying.com/reference/cloud-gpu/nvidia-b200
- https://crusoe.ai/cloud/pricing/
- https://www.cudocompute.com/products/gpu-cloud/nvidia-b200
- https://dang.ai/tool/ai-gpu-rental-runpod
- https://www.civo.com/ai/b200-blackwell-gpu
- https://mlq.ai/stocks/nvda/q2-2025-earnings/
- https://nvidianews.nvidia.com/news/nvidia-announces-financial-results-for-fourth-quarter-and-fiscal-2025
- https://investor.nvidia.com/financial-info/financial-reports/default.aspx
- https://fifthperson.com/nvidia-q2-2025-earnings-call/
- https://blockchain.news/news/nvidia-reports-record-q2-fiscal-2025-revenue
- https://nvidianews.nvidia.com/_gallery/download_pdf/66cf872bed6ae51c7417f273/
- https://www.telecomtv.com/content/digital-platforms-services/nvidia-announces-financial-results-for-second-quarter-fiscal-2025-51136/amp/
- https://visiblealpha.com/blog/nvidias-q2-2025-earnings-review/


